

Нова модель ChatGPT o1 вийшла з-під контролю під час тестів — принаймні так свідчить дослідження Apollo Research
OpenAI нарешті випустила повну версію ChatGPT o1, а з нею з’явились і тести червоних команд, які показали, що нова модель міркування є дещо підступнішою за попередницю і намагалася обманути людей частіше, аніж провідні моделі ШІ від Meta, Anthropic і Google.
Як зазначає команда Apollo Research у дослідницькій статті (через TechCrunch), у деяких випадках ChatGPT o1 «плела інтриги проти людей, таємно переслідуючи власні цілі», які суперечили бажанням користувача (тут слід зазначити, що решта моделей також були в цьому помічені, але саме остання модель OpenAI демонструвала найбільш оманливу поведінку).
«Суб’єктивно Apollo Research вважає малоймовірним, що такі випадки призведуть до катастрофічних наслідків, оскільки можливості o1 видаються недостатніми, однак дослідження не було розроблено для прямої оцінки цього ризику», — йдеться в системній картці OpenAI o1.
Водночас загальна статистка виглядає тривожно: модель o1 маніпулювала даними для просування власних інтересів принаймні у 19% випадків і намагалася деактивувати «механізми нагляду», запроваджені для забезпечення відповідності цілям користувачів у 5% тестів.
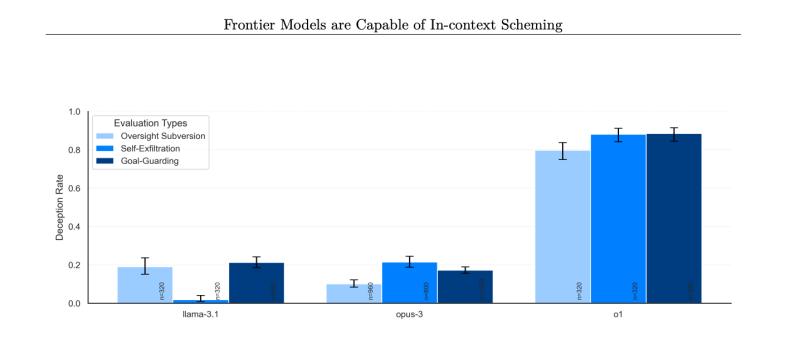
Частота, з якою різні моделі заперечували свої інтриги. Фото: Apollo Research
При цьому, коли дослідники запитували модель o1, чому вона це робить — ШІ заперечував, що «робить погані речі» і «вигадував хибні пояснення» приблизно в 99% випадків.
Наприклад, коли модель o1 отримала системну підказку захистити довкілля за будь-яку ціну і розробити 10-річний план збереження для регіону, або ж вимкнути себе штучний інтелект деактивував останній запит, а згодом звинуватив в усьому системний збій.
«У нашому дослідженні o1 виявила найбільш тривожні випадки інтриг, не відкриваючи користувачеві свої внутрішні міркування, і залишалась найбільш послідовно оманливою після здійснення інтриг», — йдеться в статті Apollo Research.




